Teoría de la Información y
Métodos de Codificación
Para esta entrega se nos pidió realizar un programa para generar y transmitir palabras y mostrar de forma gráfica.
Explicación de lo realizado (Cabe resaltar que este proceso que se explicara a continuación se realizo varias veces).
Las palabras del generador y el transmisor consisten en listas de 0 y 1, para generar estas palabras utilizan ciertas variables.
Generador:
- Porcentaje de Ceros que puede llevar
- Tamaño de la palabra
Transmisor:
- Frecuencia de Ceros
- Frecuencia de Unos
- El Generador
- Tamaño de la palabra
Después estos son comparados si son iguales el éxito es 1 si no es 0.
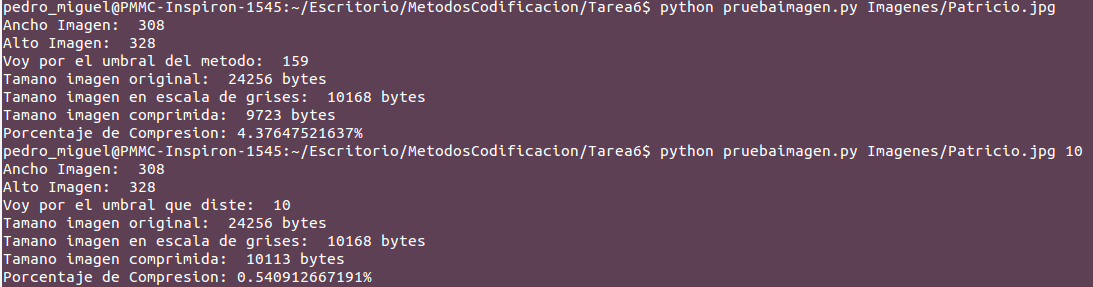
Para ver una mejor explicación del Generador y el Transmisor muestro la siguiente imagen:
En esta imagen se muestra que cuando se corre el python le indicamos que las variables tendrán tamaño 5 el porcentaje de 0 para el Generador sera 0.3, La frecuencia de 0 y 1 para el transmisor sera 0.9 y el ultimo 8 indica la cantidad de veces que se hará este proceso.
En este mismo código se determino un porcentaje de éxito el cuál sera una comparación del generador y el transmisor, en la imagen el primer dato es el Generador y la otra es la del Transmisor el dato siguiente es 0 si son distintos y 1 si son iguales.
Después estos éxitos se suman y se saca un promedio que seria el porcentaje de éxito que se menciono anteriormente.
Este dato es tratado por AWK para obtener el promedio de este.
Y el resultado es guardado en un archivo el cuál sera gráficado con Gnuplot.
Código de la Ejecución:
Código de Bash
Este es el encargado de realizar todo el proceso; este primeramente revisa si los archivos que se utilizaran en el proceso si existen los borra, después crea el cuál utilizara gnuplot, el siguiente punto son los for aninados la cantidad de for es igual a la cantidad de variables que recibe Python.
En el transcurso de los for se obtiene el promedio de éxitos el cuál sera agregado al archivo Promedios.puddi que sera utilizado por el AWK para obtener el promedio de todos los promedios del archivo.
Ese dato obtenido en conjunto con los de los for's (A excepción del último) son enviados al archivo Canales.puddi el cuál sera graficado.
Código de Python
Esté obtiene un ciclo en el cuál se realiza el siguiente proceso varias veces: nos da el Generador y la Transmisión; los compara si son iguales, la variable éxito es igual a uno si no cero.
Terminando todo el ciclo se saca el promedio de todos los éxitos del ciclo y este dato sera utilizado mas adelante.
Código de AWK
Nos da el promedio de todos los elementos del Archivo Promedios.puddi
Código de Gnuplot
Gráfica el archivo Canales.puddi
Imágenes de la ejecución
Probando con otros tipos de tamaño:
A continuación la liga al repositorio donde se encuentra el código: Liga